AI 智能体(AI Agent)是以大语言模型(LLM)为核心,能够感知环境、自主规划并调用工具执行任务的独立软件实体。它与传统聊天机器人的本质区别在于:它不再仅仅是响应指令的对话框,而是能像数字员工一样,独立操作软件并处理闭环业务流。
到 2026 年 3 月,AI 智能体已成为企业生产力的基础设施。过去两年的实践证明,单纯通过 Prompt Engineering(提示工程)难以解决复杂的业务闭环,真正的突破在于将 LLM 的推理能力与外部工具(Tools)和记忆系统(Memory)解耦并重新整合。这意味着智能体可以独立完成从调研、分析到执行的完整链路,无需人类在每一步点击确认。
核心原理解析:从线性响应到循环执行
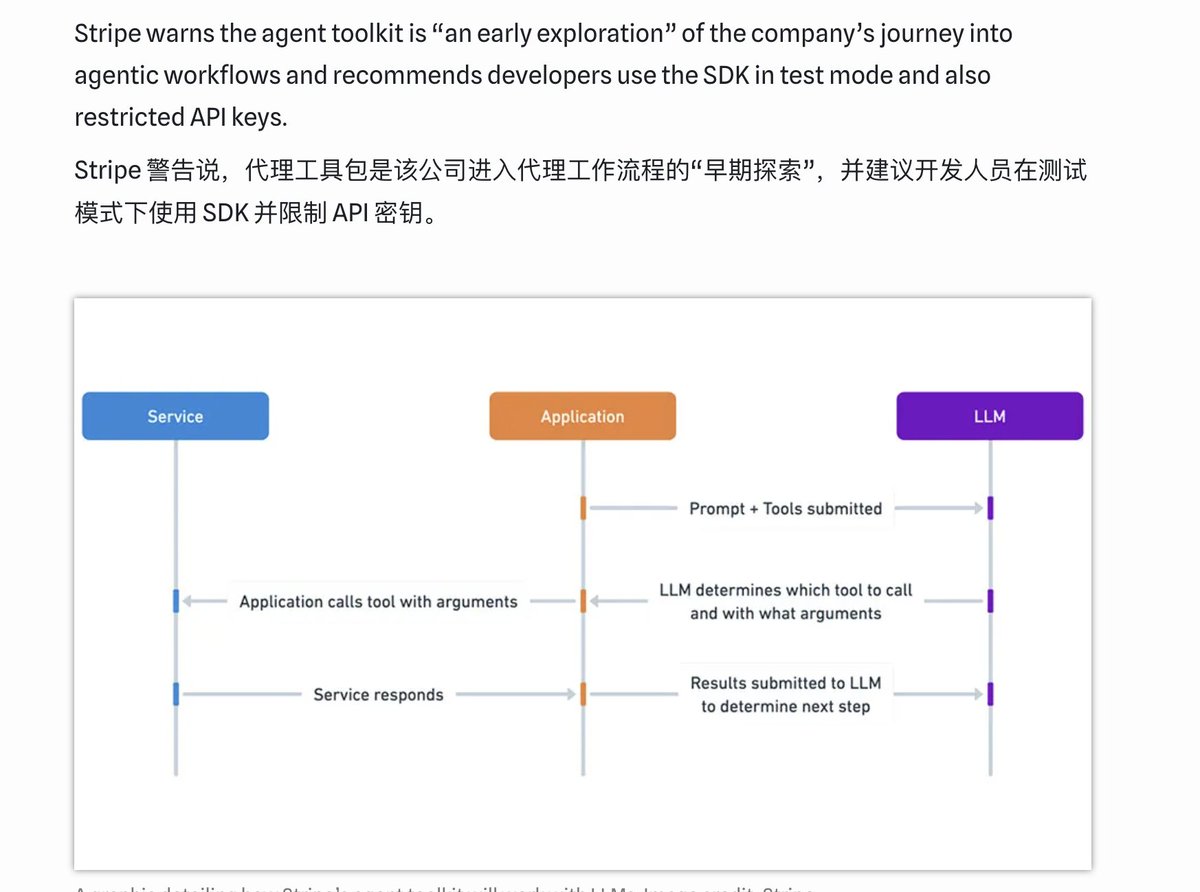
智能体采用循环逻辑而非线性响应,实现了从“对话”到“执行”的跨越。 聊天机器人的逻辑是线性的:输入 $\rightarrow$ 处理 $\rightarrow$ 输出。而智能体采用循环逻辑:感知 $\rightarrow$ 规划 $\rightarrow$ 行动 $\rightarrow$ 观察 $\rightarrow$ 修正。
这种运行逻辑通常基于 ReAct 框架(Reason + Act)。智能体首先将复杂目标拆解为子任务(规划),判断当前需调用哪个 API(行动),读取返回结果(观察),最后决定任务是否结束或需要调整方向(修正)。
该机制依赖三个关键组件:
- 规划能力: 利用思维链(Chain of Thought)拆解目标。例如,会计智能体处理发票时,必须按“识别供应商 $\rightarrow$ 检索税率 $\rightarrow$ 填入账单”的顺序执行,任何步骤缺失都会导致结果错误。
- 记忆系统: 短期记忆依赖上下文窗口(Context Window),长期记忆则基于向量数据库(如 Milvus 或 Pinecone)。这使得智能体能记录客户在数月前提出的特殊偏好,并在当前交互中自动应用。
- 工具集: 这是智能体的执行端。通过 JSON Schema 描述,LLM 能决定何时调用搜索接口、运行 Python 代码或发送 Slack 消息。
实操指南:构建自动化财务辅助 Agent
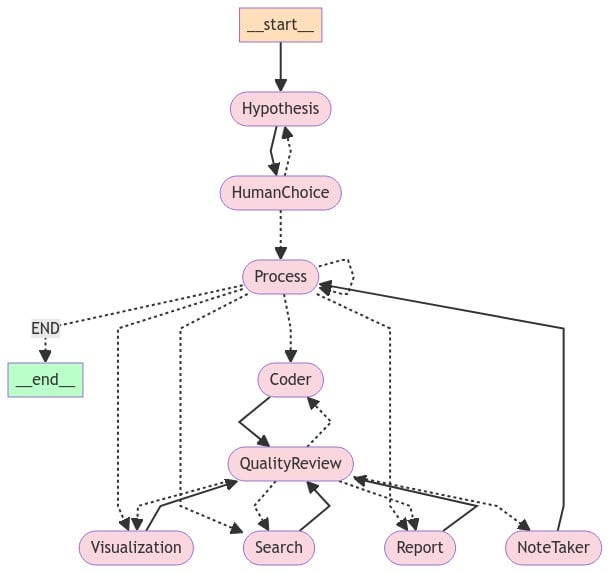
构建可运行的智能体需要严谨的工程设计,而非简单的提示词堆砌。 以下基于 CrewAI 框架,实现一个自动研究供应商并更新税码的财务辅助智能体。
选择支持多 Agent 协同的框架,如 CrewAI。准备 Python 3.11+ 环境,执行
pip install crewai langchain_openai。建议使用 .env 文件管理 API Key,避免硬编码导致的安全漏洞。在 CrewAI 中,需定义具有明确人格(Persona)的实例,以降低执行时的“幻觉”概率:供应商研究员(Vendor Researcher)负责检索信息,税务合规官(Tax Compliance Officer)负责匹配税收编码。
为研究员配置 Serper.dev 或 Tavily AI 等搜索工具。在代码中实例化
SerperDevTool 并将其分配给 agent_researcher。在 Prompt 中约束其仅提取官网 'About Us' 或 'Tax ID' 页面,过滤广告链接。定义 Task 1(搜索供应商)与 Task 2(匹配税码)。将任务放入 Crew 类中,设置
process=Process.sequential(顺序执行)。执行 crew.kickoff(inputs={'vendor_name': '某公司'}) 后,系统将自动完成完整链路。技术选型:Python 与 Go 的工程博弈

在 AI 智能体开发中,Python 占据生态优势,而 Go 在高性能部署场景中更具竞争力。
| 维度 | Python | Go (Golang) |
|---|---|---|
| 开发速度 | 极快 (生态丰富) | 中等 |
| 并发处理 | 受 GIL 限制,较弱 | 极强 (Goroutines) |
| 类型安全 | 动态类型 (运行时易错) | 强类型 (编译期校验) |
| 生态丰富度 | 统治级 (LangChain/CrewAI) | 增长中 |
建议: 原型验证或内部小工具选 Python;支撑百万级请求的商业化平台,建议调度层用 Go,模型适配层保留 Python 接口。
边界条件与局限性
AI 智能体并非万能,其随机性与延迟决定了它无法完全替代人类决策。
- 零容忍的精确计算: 如银行最终对账。由于 LLM 存在随机性,应采用“LLM 触发 $\rightarrow$ 硬编码程序执行 $\rightarrow$ LLM 总结”的半自动化模式。
- 极高实时性场景: ReAct 循环(思考-行动-观察)存在天然延迟,无法满足 100 毫秒级响应的需求(如高频交易)。
- 主观价值决策: 在企业战略调整、人事裁员等敏感决策中,它只能作为信息提供者,不能替代决策者。
如何评估一个 Agent 的成功率?
不能仅依赖单一的回答正确率,而应建立“端到端链路成功率”指标。通过构建基准测试集(Evaluation Set),对比 Agent 最终输出结果与标准答案的匹配度,并统计其中间步骤(Thought/Action)的正确率,识别是规划失败还是工具调用失败。
Agent 陷入死循环(Loop)怎么办?
这是 ReAct 模式的常见问题。建议在工程上设置
max_iterations(最大迭代次数)阈值。当 Agent 连续 3-5 次尝试相同工具且结果无变化时,强制触发“回退机制”,将任务交由人类干预或尝试切换不同的规划策略。行动建议
不要试图构建“全能助手”,应从具体的工作流切入。 寻找一个每天重复 3 次以上、且涉及 2 个以上软件界面跳转的任务(如:邮件提取订单 $\rightarrow$ ERP 查询库存 $\rightarrow$ Excel 记录状态)。
先使用 CrewAI 或 NoClick 搭建最小可行性产品(MVP),验证单一链路的成功率。在闭环稳定后再引入记忆系统或跨角色协同。智能体的竞争力不在于模型参数量,而在于工具边界的定义和任务拆解的精细度。